
[Kotlin] 스터디 Kotlin Coroutine: Deep Dive 18-20장
Kotlin coroutine: Deep Dive 책 스터디 정리 포스트
18-20장(3부) 에 해당하는 내용입니다.
18-20장(3부) 에 해당하는 내용입니다.
18장. 핫 데이터 소스와 콜드 데이터 소스
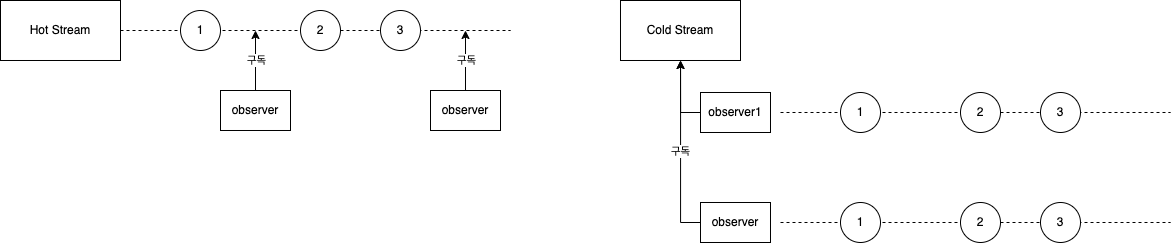
데이터 소스는 두 가지로 구분할 수 있습니다.
- Hot
- 즉시 실행되어 구독자 없이도 데이터를 계속 발행
- 구독자는 구독 시점 이후에 발행된 데이터를 소비할 수 있음
- Channel
- Cold
- 구독자가 요청 하면 데이터를 처음부터 발행
- Flow
19장. 플로우란 무엇인가
플로우는 비동기적으로 계산해야 하는 값의 스트림, 실행할 연산을 정의한 것입니다.
Flow 인터페이스에는 collect()가 있고, 이를 통해 flow가 종료될 때까지 발행되는 각 값들을 받아와 처리할 수 있습니다.
collect는 중단 함수이지만, flow 빌더는 중단 함수가 아니기 때문에 코루틴 스코프 외부에서 사용 가능합니다.
interface Flow<out T> {
suspend fun collect(collector: FlowCollector<T>)
}
여러 개의 값을 반환하는 함수가 필요할 때 사용할 수 있으나, Set, List 등과 같은 컬렉션과는 차이가 있습니다.
- 컬렉션의 경우
- 모든 원소의 계산이 완료될 때까지 기다려야 함
- 플로우의 경우
- 원소가 나오자마자 바로 계산이 가능
- sequence와 유사하며 sequence는 내부에서 suspend 함수를 사용할 수 없는 반면, flow는 내부에서 suspend 함수를 사용 가능
때문에, 플로우는 코루틴을 사용해야 하는 데이터 스트림으로 사용해야 합니다.
20장. 플로우의 실제 구현
«실제로 구현하는 과정은 생략»
플로우는 아래 순서로 동작합니다.
- collect (최종 연산) 호출
- flow 빌더 생성 시 전달된 람다 실행
- 람다식 내에서 emit 발생
- 중간 연산이 있다면 계산
- collect에 전달된 람다 실행
플로우에서 각각의 데이터 처리는 동기로 동작합니다. 즉, 최종 연산에서 처리가 완료될 때까지는 다음 값의 소비가 이루어지지 않습니다.
suspend fun main() {
flowOf("A", "B", "C")
.onEach { delay(1000) }
.collect { println(it) }
}
// 출력
A
B // 1초뒤
C // 1초뒤
동기로 동작하기 때문에 플로우 내부에 정의한 상태는 따로 동기화가 필요하지 않습니다.
플로우 외부에 상태를 정의한 경우에는 동기화가 필요합니다.
// 동기화 불필요
fun Flow<*>.counter() = flow<Int> {
// flow 내부의 상태
var counter = 0
collect {
counter ++
// busy work
counter
}
}
// 동기화 필요
fun Flow<*>.counter(): Flow<Int> {
// flow 외부의 상태
var counter = 0
return this.map {
counter ++
// busy work
counter
}
}
Comments